Los errores por ORA-00060 Deadlock, como siempre nos recuerdan desde soporte de Oracle, no son errores de la base de datos propiamente dichos. Son errores provocados por una mala implementación de código.
El propio soporte de Oracle ofrece bastantes recursos y documentación para localizar el origen de estos errores y poder aplicar las correcciones necesarias a nuestra base de datos.
En el caso que me ocupa, se detectó una disminución del rendimiento de una base de datos por interbloqueos. Es decir: ORA-00060 Deadlock.
Después de consultar distintos documentos en soporte Oracle y varias fuentes en Internet, se localizó el origen de los interbloqueos y se aplicaron las medidas correctivas pertinentes. Los pasos que seguimos fueron los siguientes.
A través de soporte Oracle se localizó el documento HOWTO «How to Identify ORA-00060 Deadlock Types Using Deadlock Graphs in Trace» (Doc ID 1507093.1). En este documento nos ayudan a interpretar las trazas que se generan cada vez que Oracle detecta un interbloqueo o deadlock. La tipología que se presentaba en nuestro caso era la siguiente:
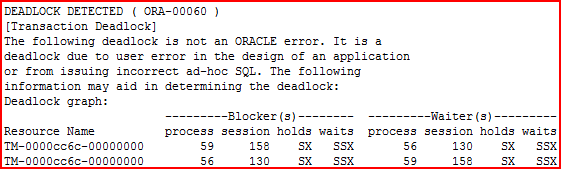
Este extracto contiene la información más importante del fichero de traza a la hora de catalogar el deadlock y buscar la solución más conveniente. Hay que prestar especial atención a las columnas marcadas en amarillo:
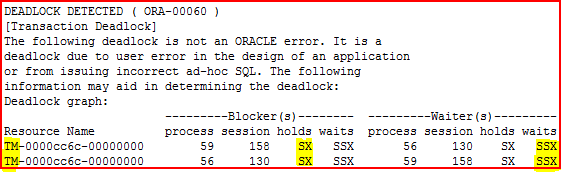
Como puede apreciarse, nuestro caso correspondía a la tipología «TM SX SSX SX SSX» que indica la necesidad de generar índices para apoyar la verificación de claves externas. Especialmente cuando se producen muchas operaciones de inserción y actualización en lotes.
Bueno, pues una vez identificado el problema teníamos que buscar la solución más conveniente. ¡Manos a la obra!. En primer lugar teníamos que localizar los índices que era necesario crear y lanzar una batería de pruebas que confirmara el cese de los interbloqueos. Gracias al blog de Tom Kyte pudimos ahorrarnos el trabajo de generar una consulta que nos localizara estos índices. La consulta que nos ofrece Tom Kyte es la siguiente:
select *
from (
select table_name, constraint_name,
cname1 || nvl2(cname2,','||cname2,null) ||
nvl2(cname3,','||cname3,null) || nvl2(cname4,','||cname4,null) ||
nvl2(cname5,','||cname5,null) || nvl2(cname6,','||cname6,null) ||
nvl2(cname7,','||cname7,null) || nvl2(cname8,','||cname8,null)
columns
from ( select b.table_name,
b.constraint_name,
max(decode( position, 1, column_name, null )) cname1,
max(decode( position, 2, column_name, null )) cname2,
max(decode( position, 3, column_name, null )) cname3,
max(decode( position, 4, column_name, null )) cname4,
max(decode( position, 5, column_name, null )) cname5,
max(decode( position, 6, column_name, null )) cname6,
max(decode( position, 7, column_name, null )) cname7,
max(decode( position, 8, column_name, null )) cname8,
count(*) col_cnt
from (select substr(table_name,1,30) table_name,
substr(constraint_name,1,30) constraint_name,
substr(column_name,1,30) column_name,
position
from user_cons_columns ) a,
user_constraints b
where a.constraint_name = b.constraint_name
and b.constraint_type = 'R'
group by b.table_name, b.constraint_name
) cons
where col_cnt > ALL
( select count(*)
from user_ind_columns i
where i.table_name = cons.table_name
and i.column_name in (cname1, cname2, cname3, cname4,
cname5, cname6, cname7, cname8 )
and i.column_position < = cons.col_cnt
group by i.index_name
)
);
Esta consulta devuelve todas las claves externas que no disponen de un índice de apoyo, dentro de las constraints pertenecientes al usuario conectado. La consulta se encuentra en la siguiente entrada de su blog:
Tom Kyte – Thanks for the question regarding «Rows locks from select for update clause»
Sobre estos datos, hay que seleccionar las claves externas para la que nos interesa crear índices. No siempre es bueno crear índices para claves externas, como indica Tom Kyte en otra entrada de su blog:
Tom Kyte – Thanks for the question regarding «Indexes on foreign keys»
Una vez seleccionados los índices que consideremos necesarios en cada caso, se pueden generar volviendo a lanzar la sentencia de Tom Kyte con la siguiente cláusula select:
select 'create index '||constraint_name||' on '||table_name||' ('||columns||');' script
La tarea de seleccionar los índices pasa por identificar las tablas afectadas por los interbloqueos. Gracias a los Deadlock Graphs de las trazas capturadas y con una simple consulta al diccionario de datos, podemos obtener este dato. Los datos en hexadecimal que siguen al tipo de bloqueo dentro de la traza corresponden al identificador del objeto en la base de datos. En nuestro ejemplo el dato a verificar es el siguiente:
TM-0000cc6c-00000000
Y con la siguiente consulta, obtenemos el nombre del objeto:
select *
from dba_objects
where object_id in (TO_NUMBER('0000cc6c', 'XXXXXXXX'))




