select idfrom json_table(json_array(1,2,3,4 returning blob) format json, '$[*]'columns ( id number path '$'));
ID
----------
1
2
3
4
select idfrom json_table(json_array(1,2,3,4 returning blob) format json, '$[*]'columns ( id number path '$'));
ID
----------
1
2
3
4Estas consultas están tomadas del siguiente artículo de Chris Saxon en el que explica con más detalle los detalles y excepciones a tener en cuenta:
How to convert UNIX epochs to datetime values in Oracle Database
Las consultas utilizadas son las siguientes:
-- Epoch to time: datetime and timestamp
select to_date('01/01/1970','dd/mm/yyyy') + (:epoch / 86400) epoc_dt,
to_timestamp('01/01/1970 00:00:00', 'dd/mm/yyyy hh24:mi:ss') + numtodsinterval (:epoch, 'second') epoc_ts
from dual;
-- Time to epoch: datetime
select round((to_date(:datetime, 'dd/mm/yyyy hh24:mi:ss') - to_date('01/01/1970','dd/mm/yyyy')) * 86400) dt_epoch
from dual;
-- Time to epoch: timestamp
select extract(day from epoch_dsi) * 86400
+ extract(hour from epoch_dsi) * 3600
+ extract(minute from epoch_dsi) * 60
/* remove fractional seconds */
+ trunc(extract(second from epoch_dsi)) ts_epoch
from (select to_timestamp(:datetime, 'dd/mm/yyyy hh24:mi:ss') - to_timestamp('01/01/1970 00:00:00', 'dd/mm/yyyy hh24:mi:ss') epoch_dsi
from dual);
Una expresión regular para enmascarar teléfonos (con prefijo internacional).
SELECT result1 ORIGINAL_PHONE,
regexp_replace(
regexp_replace(result1,'[^[:digit:]+]',''), -- Remove non-digit and special phone characters
'^(00[[:digit:]]{2}|\+[[:digit:]]{2})([[:alnum:]]*)([[:alnum:]]{3})$', -- Phone pattern
'\1*\3') MASK_PHONE -- Mask
FROM (
WITH test AS
(SELECT '0034910000000,+34910000000' col1 FROM dual)
SELECT regexp_substr(col1, '[^,]+', 1, rownum) result1
FROM test
CONNECT BY LEVEL <= regexp_count(col1, ',') + 1);
El resultado es:
ORIGINAL_PHONE MASK_PHONE
---------------- ----------------
0034910000000 0034*000
+34910000000 +34*000Una expresión regular para enmascarar correos electrónicos.
SELECT result1 ORIGINAL_EMAIL,
regexp_replace(
regexp_replace(result1, '[^[:alnum:]._%+-@]', ''), -- Remove non-digit, non-alphabetic and special email characters
'^([[:alnum:]._%+-]{2})([[:alnum:]._%+-]*)(@)([[:alnum:]._%+-]{2})([[:alnum:]._%+-]*)(\.{1}[[:alpha:]]{2,}$)', -- Email pattern
'\1*\3\4*\6') MASK_EMAIL -- Mask
FROM (
WITH test AS
(SELECT 'n.surname@domain.ext,nsurname@subd.domain.ext,name-surname@domain.ext' col1 FROM dual)
SELECT regexp_substr(col1, '[^,]+', 1, rownum) result1
FROM test
CONNECT BY LEVEL <= regexp_count(col1, ',') + 1);
El resultado es:
ORIGINAL_EMAIL MASK_EMAIL
-------------------------------- -------------
n.surname@domain.ext n.*@do*.ext
nsurname@subd.domain.ext ns*@su*.ext
name-surname@domain.ext na*@do*.extSelect para extraer de un JSON los elementos un nodo de tipo lista.
select id
from json_table('{"list_ids": [1,2,3,4]}'
format json, '$.list_ids[*]'
columns (
id number path '$'));
ID
----------
1
2
3
4
Select para extraer datos de un JSON que informa varios items.
select id, nombre, familia
from json_table('[{id: 1, name: "Naranja", family: "Cítrico"},
{id: 2, name: "Tomate", family: "Hortaliza"}]'
format json, '$[*]'
columns (
id number path '$.id',
nombre varchar2 path '$.name',
familia varchar2 path '$.family'));
ID NOMBRE FAMILIA
----- --------------- ---------------
1 Naranja Cítrico
2 Tomate HortalizaLa consulta siguiente muestra la conversión del formato de fechas RFC3339, muy común en servicios REST y objetos JSON, al timpo de dato timestamp nativo en Oracle.
select TO_TIMESTAMP_TZ('2020-12-15T15:20:28Z', 'YYYY-MM-DD"T"HH24:MI:SS.FF9TZH:TZM') as RFC3339_to_timestamp_zulu,
TO_TIMESTAMP_TZ('2020-12-15T15:20:28Z', 'YYYY-MM-DD"T"HH24:MI:SS.FF9TZH:TZM') AT TIME ZONE 'Europe/Madrid' as RFC3339_to_timestamp_madrid
from dual;
RFC3339_TO_TIMESTAMP_ZULU RFC3339_TO_TIMESTAMP_MADRID
--------------------------------- -------------------------------------------
15/12/2020 15:20:28,000000000 GMT 15/12/2020 16:20:28,000000000 EUROPE/MADRIDHace unos días saltó un error al confirmar una inserción en Oracle. El error se producía a la hora de refrescar una vista materializada en modo «fast refresh on commit». Pero la descripción del error no ofrecía mucha información:
ORA-12008: error in materialized view refresh path
ORA-00904: "<column_name>": invalid identifierEn el error 904 nos informaba de una de las columnas de la tabla sobre la que está construida la vista materializada. Pero esta columna no tenía ninguna característica particular: es de tipo varchar2 (no de un tipo de datos complejo), no está indexada, no tiene referencias externas con otras tablas; además, en la sentencia INSERT que daba el error venía informada con datos admisibles. ¿Qué puede estar ocurriendo?
Después de lanzar varios refrescos de la vista materializada, cambiando distintas opciones sin que nos dieran error, y comprobando que las inserciones seguían fallando: ¿por dónde seguimos investigando?
Comenzamos a realizar búsquedas en MOS con los códigos de error, acotando por versión de la base de datos, y dimos con la nota ID 1331516.1 «Errors ORA-12008 And ORA-904 Invalid Identifier While Fast Refreshing».
La nota reconoce este comportamiento como un bug de las versiones 11.2 que se corrigen en la 12.1. Bueno, esto ya es algo. El problema ahora es que nuestra base de datos ya está en versión 12. En teoría, el bug estaba corregido.
De todas formas, revisamos la nota completa y nos llamó la atención el parche temporal que proponían:
alter system set "_replace_virtual_columns" = FALSE;¿Hay que desactivar el reemplazo de columnas virtuales? Nosotros no utilizamos columnas virtuales en la tabla sobre la que se construye la vista materializada. ¿O si? Vamos a averiguarlo:
select * from user_tab_cols where table_name = '<table_name>' and virtual_column = 'YES';Pues resulta que si tenemos columnas virtuales. Y, ¿de dónde han salido? El nombre de las columnas es un nombre generado por el sistema. Así que alguna funcionalidad interna de Oracle está creando columnas virtuales en la tabla. Y, tal vez, estén interfiriendo en el refresco de las vistas materializadas. Para salir de dudas, buscamos la forma de eliminar las columnas virtuales y damos con el post de Chris Saxon sobre el misterio de las columnas virtuales:
https://blogs.oracle.com/sql/ora-54033-and-the-hidden-virtual-column-mystery
Parece ser que las estadísticas extendidas de Oracle han decidido crear estas columnas virtuales para mejorar sus reportes de rendimiento. Y una de ellas contiene la columna que se refería en el error ORA-00904. Como no creemos en las casualidades, y esto ya es mucha casualidad, decidimos eliminar la columna virtual sospechosa. En este mismo artículo explican cómo hacerlo:
exec dbms_stats.drop_extended_stats(user, '<table_name>', '(<x, y>)');Y, efectivamente, el refresco de la vista materializada ha vuelto a funcionar.
On numerous occasions I said: Why are we doing that ? We already have it!
Customers pay serious money for their Oracle Database. The problem is that neither the customer nor the developers tend to know the product. They still think the Oracle database is…well just a very very very expensive bucket. I tried to find a picture which actually shows what you bought. Couldn’t find any, so I made my own.Not pretty but’s that’s not the point. 🙂
If you are running Oracle Enterprise Edition 11g/12c this is what you roughly have without any extra licenses. Know what you pay for. Use what you pay for.
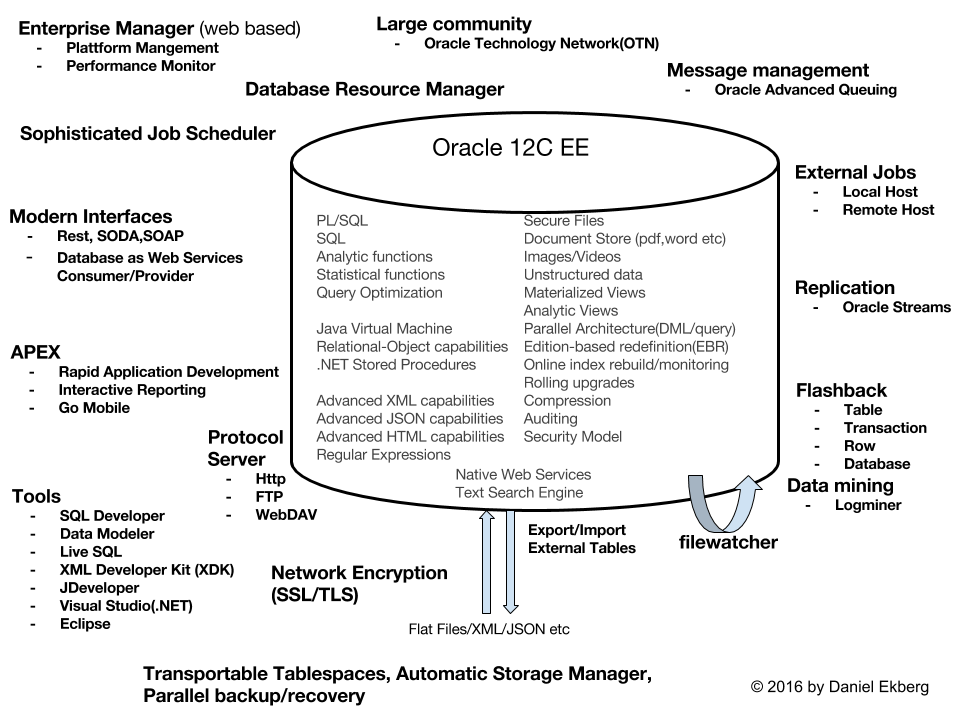
On purpose , the level of detail is restricted in this picture. Also Oracle Streams «cannot be used» with multitenant container databases (CDBs) or pluggable databases (PDBs). Too bad, I guess Golden Gate is the replacer for that?
If I missed out any obvious…
Ver la entrada original 6 palabras más
En la presentación realizada por Larry Ellison en Oracle OpenWorld 2017 ha destacado que la nueva versión de la base de datos Oracle 18c incorporará la capacidad de realizar la siguientes tareas de manera autónoma:
Entre otras tareas de administración menores. Los procesos que van a gestionar estas tareas se basan en algoritmos Machine Learning (ML) que permiten a la base de datos adaptarse a distintos escenarios y mejorar sus prestaciones.
Los detalles de la presentación han sido publicados en el siguiente enlace: Larry Ellison on Oracle’s “self-driving” database.
